1. 클라이언트 NLS_LANG
많은 오라클 엔지니어들이 아직도 이경우 제대로 정리되지 않은 부분입니다.
결론부터 말하면 DB의 CHAR SET이 UTF8이라고 하더라도
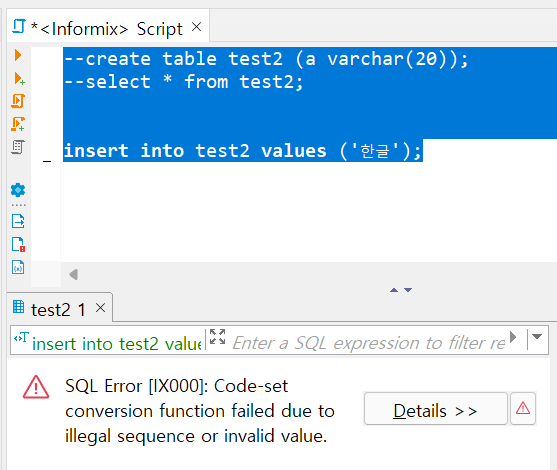
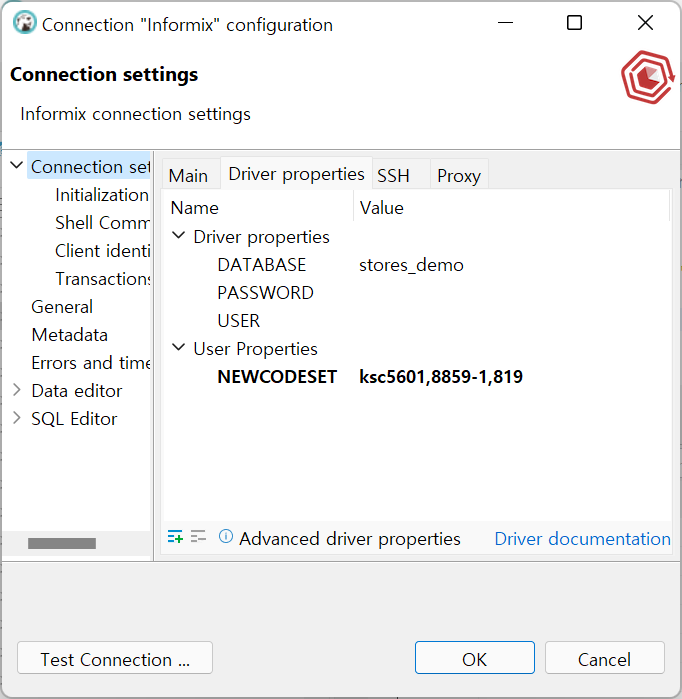
클라이언트 LOCALE은 KSC5601 혹은 WIN949이어야 합니다.
문서도 있는데 링크는 기억나지 않고^^;
UTF8이 서버 로케일일 경우이건 뭐건, 클라이언트 로케일은 해당 국가 로케일이 되어야 합니다.
간략한 테스트는
LENGTHB와 CONVERT 함수를 이용해서 테스트를 해보면 됩니다.
DB가 UTF8일 경우
클라이언트 LOCALE이 UTF8로 올릴 경우 한글이 2바이트로 됩니다.
CONVERT로 바꿀 때 SOURCE를 KOC5601로 처리해야 됩니다. (하지만 DUMP를 떠보면 다르게 나옵니다)
DB가 UTF8이라고 클라이언트 로케일을 UTF8로 바꿀 경우 치러야 할 대가가 만만치 않습니다.
특히 EXPORT,IMPORT할 때 NLS_LANG을 잘못한 경우...--;
2. CHAR TYPE 문제
하나의 칼럼이 CHAR TYPE인데 이를 UTF8로 바꾼다면?
해당 데이터가 오로지 영숫자만 있다면 상관없겠으나
한글도 들어간 칼럼이라면?
DATA TYPE 변경 없이 일괄적으로 칼럼의 LENGTH를 늘리면
스페이스가 들어가는 경우가 발생합니다.
즉, CONVERSION이 잘못된 경우이죠.
이때는 먼저 SOURCE에서 CHAR -> VARCHAR2로 변경한 뒤에 작업하셔야 합니다.
일반적으로 특수한 경우(좀있다 얘기하겠습니다)를 제외하고 이렇게 변경한 뒤에
어플리케이션 영향도는 없다고 보셔도 됩니다.
그리고 변경하는데 생기는 부하는 거의 없습니다. 단, 피크시간대는 절대 피하셔야죠
LIBRARY CACHE 쪽에서 해당 테이블을 참조하는 오브젝트가 모두 재컴파일 됩니다.
3. VARCHAR2(4000)칼럼의 문제
LOB나 LONG을 사용하지 않고 VARCHAR2로 칼럼을 정의하고 게시판 본문이나
각종 텍스트를 처리하는 테이블이 있습니다.
이 경우 UTF8로 넘어갈 때 BYTE가 늘어나 해당 레코드를 처리할 때 에러가 납니다.
EXP를 사용할 경우 그냥 에러로그에 남으니까 그나마 낳습니다.
DB LINK로 땡길 경우 전체 트랜잭션이 에러나면 많이 힘들게 되죠.
그리고 실질적으로 VARCHAR2(4000)을 넘기 때문에 데이터가 잘리는 문제가 생깁니다.
이를 해결하려면 LOB로 바꿔야 하는데 이경우 어플리케이션 테스트를 제대로 못하면 문제가 커집니다.
JAVA같은 경우 TYPE문제가 걸리죠
이경우 최선의 방법은 없습니다.
저같은 경우 어플리케이션 담당자를 설득해서 해당 칼럼 데이터의 나머지를 버렸습니다.
물론 당근으로는... LOB로 바꿀 경우 어플리케이션을 바꿔야 한다는 것. 하지만 일부 데이터의 OVER LENGTH부분을
버리면 아무것도 손댈 필요가 없다는 것...
아무튼, 이부분은 DBA가 단독으로 결정하면 안됩니다.
4. UTL_FILE을 이용한 FILE CONTROL 문제
이건 상당히 골치 아픈 문제입니다.
대상 DB와 어플리케이션이 UTL_FILE을 사용해서 데이터를 읽거나 쓰지 않는다면 여러분은 일단 복받으신 겁니다.
일반적으로 소켓으로 주고받는 데이터(뭐 금융권 전문이나 애니링크같은)는 구분자가 아니라 자리수로 구분합니다.
FILE에서는 한글2바이트,영문1바이트이기 때문에 그걸로 미리 자리수가 정해져 있죠.
이를 UTL_FILE이나 LOADER로 올려서 SUBSTRB로 잘라서 쓰는 경우가 있습니다.
그런데 디비에서 처리하면 한글3바이트,영문1바이트입니다. 즉, 정해진 자리수로 자를 수 없습니다.
당연히 배치에서 데이터가 잘못 처리됩니다.
이럴 때 첫번째로 생각하는 방법은 CONVERT로 KSC5601로 바꿔서 기존 데이터 처리 방식으로 처리하면 됩니다.
하지만 이런 경우에도 글자는 깨집니다. 왜냐하면 SUBSTRB(SUBSTR 포함)는 해당 로케일을 따라가기 때문에
CONVERT로 바꾼다고 해도 보장을 못합니다.
이를 해결할려면 UTL_RAW 팩키지를 사용해야 합니다.
특히, 잘라서 올리는 것만이 아니라 자리수에 맞춰서 UTL_FILE로 WRITE 할 경우 CONVERT를 제대로 안하면
전문처리 등에서 대형사고를 일으킵니다.
5. PARTIAL MULTI BYTE 에러
이는 KSC5601 -> UTF8로 DB LINK로 처리할 때 많이 생깁니다.
원인은 KSC5601 자체 있습니다.
UTF 코드는 자신이 파싱 못하는 문자는 받아들이지 않으나 KSC5601은 다 받아들입니다.
즉, 파싱되지 않는 쓰레기 데이터도 해당 칼럼에 들어갑니다.(예를 들어 ¿ 같은 문자)
그나마 눈에 보이는 문자면 다행이죠... 아예 조회시 누락되는 바이트도 있습니다.
물론 TO_SINGLE_BYTE FUNCTION으로 대부분 해결됩니다. 그래서 가능한 이방식을 먼저 적용합니다.
하지만 그렇게 되지 않는 경우도 발생합니다.
이런 경우는 일일이 찾아서 해당 데이터를 고쳐야 합니다.
제일 편한 방법은 EXPORT/IMPORT로 넣어서 ERROR LOG를 보면 됩니다.
그런데 해당 사이트에 여러개의 DB가 있고 해당 데이터가 원천데이터가 아닌 경우는 끝까지 추적해서 그걸 잡아내지 않으면
마이그레이션 이후에도 계속 에러납니다.
예를 들어 UTF로 바꾼 DB는 정보계이고 계정계는 아직 KSC5601이라면 마감배치 돌릴 때마다 에러나겠죠?
6. COLUMN LENGTH의 문제
한글은 2->3바이트, 영숫자는 1->1 바이트이므로 계산상 해당 칼럼을 1.5배로 늘려주면 아무 이상이 없어야 하는데요...
안타깝게도 안그렇습니다. 위의 PARTITAL MULTI BYTE에러와 연관되는 문제인데... 1바이트로 처리되어야하는 문자가
3바이트로 처리되는 경우가 발생합니다. 이것을 피하고 싶으면 TO_SINGLE_BYTE로 처리해야 합니다.
그러나... 이경우 문제가 있습니다. 일단 처리시간이 오래걸립니다.(마이그레이션은 제한된 시간에 해야 합니다)
그렇다고 기존 SOURCE를 전부 UPDATE처리하자니 뒷감당이 안됩니다.( 문제가 발생하는 레코드의 칼럼만
변경하면 됩니다만 이것을 추적해서 찾을 시간이 없습니다. 물론 시간이 있다면 하시는게 베스트죠. 그러나 그럴 시간을
확보할 수 있을까요?)
결국 나중에는 2배로 늘리고, 다시 2.5~3배로 늘렸습니다. 시간이 부족하기 때문에 벌어진 일이죠.
이렇게 해도 큰 문제가 없는 이유는 대부분 이런 문제를 일으키는 데이터는 조회조건에 걸리는 칼럼이 아니라
조회결과로 걸리는 칼럼이기 때문입니다.(비즈니스 어플리케이션을 이해하신다면 수긍하실겁니다)
이것은 편법입니다. 원칙적으로는 이런 데이터 클린징작업을 먼저 수행해야 합니다.