Logical Log Backups - (onbar -l) onbar will request all logical logs from the engine to be backed up and pass them to the storage manager.
Continous Logical Log Backups - (onbar -C -l ) onbar will start continous logging just like ontape -c
Fake online Backup - (onbar -b -F) onbar will tell the engine to do a 'fake' backup. This is like archiving to /dev/null. This added feature is useful if you want to change the logging mode af a database and do not have the time to perform and archive. NOTE. This does not take the place a regular archive because nothing is sent to the storage manager so nothing can be restored.
Onbar Warm Restore - (Onbar -r dbsp2 dbsp3 ...) When onbar performs a warm restore it will first have online back up all the logical so that it can roll forward through them after the physical restore. Next onBar will scan through the sysutils database to get a list of the objects it needs to get from the storage menager. once that is done, onBar will simply get the objects from the storage manager and send then to the engine to be restored. Finally onbar starts retrieving the logical log backups from the Storage Manager and send them to online to be applied as logical recovery.
Mixed restore - Obar can allow the user to perform a mixed restore. This is basically a combinations of both cold and warm restores. The user would first perform a cold restore of the cirtical dbspaces and then a warm restore of the non-critical dbspaces.
Physical restore - (onbar -r -p) As mentioned above onbar will by default start logical recovery after physical recovery has finished. If the user does not want this to happen, he/she can use the '-p' option and onbar will only perform physical recovery. once this is done, online will hang in fast recovery until onmode -m is issued.
Logical recovery - (onbar -r -l) If the user does a physical restore and then wants to perform a logical restore after that, then the user can use the '-l' option to rollforward the logs after the physical restore completes. This can't be done if modifications were done to the database between them time the physical restore completed and the logical restore startted.
Point in Time Recovery - (onbar -r -t {date and time} OR onbar -r -n {log number}) This will allow the user to restore the ENTIRE instance to a specific point in time. That time can be specified by either telling onbar what logical log to rollforward through or by telling onbar the time it is to stop rolling forward. NOTE: The point in time recovery feature is only to be used when performing a cold restore of the entire instance and will NOT work if you want to perform a warm restore of a set of dbspaces.
기업 내 다양한 업무를 신속하게 처리하는 데 있어 데이터베이스 시스템의 장애로 인해 특정 중요 테이블의 긴급 복구를 해야 할 필요가 있습니다. 물리적인 장애로 인해 테이블의 데이터를 이용하지 못하는 경우도 있고, 사용자의 실수로 인해 특정 테이블의 데이터의 손실을 유발할 수 있습니다.
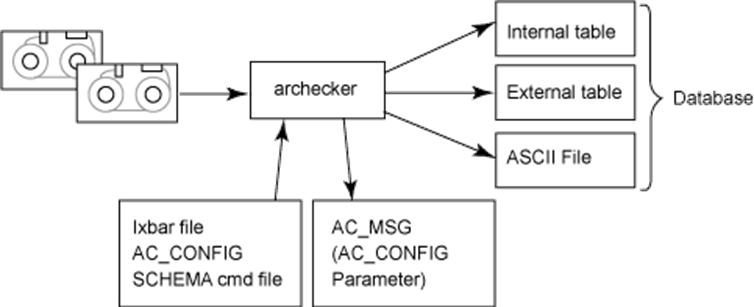
IBM Informix Dynamic server 10.0에서는 archecker 유틸리티를 사용하여 보관으로부터 특정 테이블을 복구할 수 있습니다. 복구하려는 테이블은 특정 시점까지 복원할 수 있고, 특정 범위의 데이터만 찾아 복원할 수 있습니다. 이를 사용하면 전체 보관의 복원을 수행하지 않고 데이터의 특정 조각을 복원할 수 있습니다.
Figure 1. Overview of archecker utility
사전 작업
TSM 또는 ISM을 이용하여 onbar backup을 받을 수 있는 환경을 만들어 놓습니다.
환경 설정
IDS v10에서 테이블 단위의 복구 기능을 사용하려면 archecker라는 유틸리티를 사용합니다. Archecker를 실행하기 위해 몇 가지 설정을 해야 하는 데, 인포믹스 사용자 환경과 archecker가 실행될 때 복구 범위를 참조해야 할 커맨드 파일을 작성해야 합니다.
환경변수 AC_CONFIG를 사용하여 archecker의 설정 파일의 경로를 지정합니다. onCONFIG와 마찬가지로 $INFORMIXDIR/etc/ac_config.std를 복사해서 설정 파일로 사용합니다.
현재 설치된 IDS의 환경에 맞게 AC_CONFIG에 지정된 파일을 수정합니다. AC_SCHEMA는 archecker 실행시 참조하는 커맨드 파일의 경로를 지정하는 데, 이후 ?f 옵션을 사용하여 커맨드 파일을 읽을 때는 이 값은 무시됩니다. AC_IXBAR는 onbar 백업을 받을 때 생성되는 ‘ixbar.인포믹스 서버번호’ 을 지정합니다.
[ cmdfile1.cmd ]
database stores7;
create table customer
(
customer_num serial not null ,
fname char(15),
lname char(15),
company char(20),
address1 char(20),
address2 char(20),
city char(15),
state char(2),
zipcode char(5),
phone char(18),
primary key (customer_num)
) in datadbs;
insert into customer select * from customer;
restore to '2006-03-24 21:10:08';
커맨드 파일의 작성이 끝나면 다음과 같은 명령어를 실행합니다.
# archecker -bvs -f /informix/ARCH/cmdfile1.cmd
IBM Informix Dynamic Server Version 10.00.UC4
Program Name: archecker
Version: 8.0
Released: 2005-11-18 22:22:21
CSDK: IBM Informix CSDK Version 2.90
ESQL: IBM Informix-ESQL Version 2.90.UC1
Compiled: 11/18/05 22:23 on Linux 2.4.21-27.0.2.ELsmp #1 SMP Wed Jan 12 23:35:44 EST 2005
AC_STORAGE /tmp
AC_MSGPATH /informix/ac_msg.log
AC_VERBOSE on
AC_TAPEBLOCK 62 KB
AC_IXBAR /informix/etc/ixbar.0
Dropping old log control tables
Extracting table stores7:customer into stores7:customer
Scan PASSED
Control page checks PASSED
Table checks PASSED
Table extraction commands 1
Tables found on archive 1
LOADED: stores7:customer produced 28 rows.
Creating log control tables
Staging Log 48
Logically recovered stores7:customer Inserted 0 Deleted 0 Updated 0
실행이 완료되면 데이터를 확인합니다. Customer 테이블이 생성되며 데이터가 로딩됩니다. # dbaccess stores7 - Database selected. > select count(*) from customer; (count(*)) 28 1 row(s) retrieved.
시나리오 2. 다른 테이블로 복구
운영 중인 데이터베이스 내 테이블의 특정 데이터를 실수로 삭제를 했을 경우, 현재 테이블은 보존하면서 다른 이름의 테이블을 생성하여 데이터를 복원할 수 있습니다.
delete from customer where customer_num > 120;
다음과 같이 커맨드 파일을 작성하세요. 이때 원본 테이블 이름과 다른 테이블 이름을 지정하세요.
--cmdfile2.cmd
database stores7;
create table customer
(
customer_num serial not null ,
fname char(15),
lname char(15),
company char(20),
address1 char(20),
address2 char(20),
city char(15),
state char(2),
zipcode char(5),
phone char(18),
primary key (customer_num)
) in datadbs;
create table customer2
(
customer_num serial not null ,
fname char(15),
lname char(15),
company char(20),
address1 char(20),
address2 char(20),
city char(15),
state char(2),
zipcode char(5),
phone char(18),
primary key (customer_num)
) in datadbs;
insert into customer2 select * from customer;
restore to '2006-03-24 21:10:08';
커맨드 파일의 편집이 끝나면 다음과 같은 명령어를 실행합니다. # archecker -bvs -f /informix/ARCH/cmdfile2.cmd
실행이 완료되면 데이터를 확인합니다. Customer2 테이블이 생성되며 customer 테이블의 데이터가 customer2 테이블로 로딩됩니다. 이때 customer 테이블에서 삭제된 데이터를 customer2 테이블에서 확인할 수 있습니다.
# dbaccess stores7 - Database selected. > select count(*) from customer2 where customer_num > 120;
(count(*)) 8 1 row(s) retrieved.
시나리오 3. 데이터 필터링 후 복구
DBA가 테이블 내 특정 시점의 특정 테이터 만 선별하여 복구하려 합니다. 다음과 같이 커맨드 파일을 작성하며, 이때 물리 복구만을 해야하며 ‘no log restore’ 옵션을 추가해야 합니다.
--cmdfile3.cmd
database stores7;
create table customer
(
customer_num serial not null ,
fname char(15),
lname char(15),
company char(20),
address1 char(20),
address2 char(20),
city char(15),
state char(2),
zipcode char(5),
phone char(18),
primary key (customer_num)
) in datadbs;
create table customer3
(
customer_num serial not null ,
fname char(15),
lname char(15),
company char(20),
address1 char(20),
address2 char(20),
city char(15),
state char(2),
zipcode char(5),
phone char(18),
primary key (customer_num)
) in datadbs;
insert into customer3 select fname,lname from customer where customer_num > 120;
restore to '2006-03-24 21:10:08’
no log restore;
커맨드 파일의 편집이 끝나면 다음과 같은 명령어를 실행합니다. # archecker -bvs -f /informix/ARCH/cmdfile3.cmd
실행이 완료되면 데이터를 확인합니다.
# dbaccess stores7 - Database selected. > select count(*) from customer3 where customer_num > 120;
(count(*)) 8 1 row(s) retrieved.
시나리오 4. ASCII 데이터 파일로 테이블 복구
백업 디바이스 내에 백업된 테이블 데이터를 데이터베이스 내의 테이블이 아닌 ASCII의 파일 형태로 복구하려고 합니다. 다음과 같이 커맨드 파일을 작성하며, ‘external’로 표시되는 가상의 타겟 테이블을 정의해야 합니다.
--cmdfile4.cmd
database stores7;
create table customer
(
customer_num serial not null ,
fname char(15),
lname char(15),
company char(20),
address1 char(20),
address2 char(20),
city char(15),
state char(2),
zipcode char(5),
phone char(18),
primary key (customer_num)
) in datadbs;
create external table customer4
(
customer_num serial not null ,
fname char(15),
lname char(15),
company char(20),
address1 char(20),
address2 char(20),
city char(15),
state char(2),
zipcode char(5),
phone char(18)
) using ('/tmp/customer.unl',delimited);
insert into customer4 select * from customer;
restore to '2006-03-24 21:10:08’ no log restore;
커맨드 파일의 편집이 끝나면 다음과 같은 명령어를 실행합니다. # archecker -bvs -f cmdfile4.cmd
customer 테이블의 데이터를 추출하여 “|”를 구분자로 customer.unl 데이터 파일을 생성합니다. 실제 customer.unl 파일이 생성되었는지 확인하십시오.
MustGather information for problems with down dbspaces/chunks. Gathering this information before calling IBM® support helps familiarize you with the troubleshooting process and saves you time.
Answer
Gathering general information For IBM® Informix® products, gather the following information for any problem:
Are the chunks stored in an external disk array cabinet (or similar hardware)?
If more than one chunk has been marked down, are those chunks handled through the same disk controller? (onstat -d , although you may have to check the devices if using links)
How many other instances exist on this machine? (onstat -g dis)
Was a new chunk recently added to this instance? (oncheck -pr)
If there are other instances on the same machine, were a chunk was recently added?
Is there recent backup of the system? (onstat -g arc, oncheck -pr)
Is it possible to dial into, or somehow connect to, the system?
Processes to run
Read the operating system man pages and IDS documentation for usage and other information about the following commands, if necessary. Run the following commands and collect the output:
On UNIX or Linux: run ps -ef to collect a list of the currently running processes.
On UNIX or Linux: run ls -lL to check whether the chunk exists and has the correct permissions. The permissions should be 660 and the owner/group should both be informix.
On UNIX and Linux: If the chunk exists, run a dd command to see if any errors are reported or whether the chunk is accessible:
Adjust "bs" to be the page size of the dbspace in question. Adjust iseek if there has been an offset used when the chunk was added. (The above information can be ontained from an onstat -d").
Run oncheck -pr to gather detailed information about the IDS reserved pages. Some of the useful information from this report are:
"Page Size" from PAGE_PZERO
MSGPATH, DBSPACETEMP, DUMPDIR, onDBSPACEDOWN from PAGE_CONFIG".
If the IDS engine is online, run onstat -d.
If the IDS engine is online, run onstat -b.
Run oninit -V to obtain the exact IDS version being run.
On UNIX, run uname -a to obtain the O/S version. If running on AIX, also run oslevel -s.
Files to collect
This section lists files to collect which are normally (or optimally) analyzed for this problem.
Any core files generated during the problem.
If there is a core file generated, please also supply the binary that was running, which in most cases will be the oninit binary from $INFORMIXDIR/bin directory.
The whole online.log or the relevant portion from the online.log if it is large.
Any Assertion file that was reported at the time of the issue.
Errors reported to the Front End application.
The relevant hardware log from the machine.
Submitting information to IBM Support
Once you have collected your information, you can begin Problem Determination through the product Support web page, or simply submit the diagnostic information to IBM support.
You can submit files using one of following methods to help speed problem diagnosis:
IBM Support Assistant (ISA)
Electronic Service Request (ESR)
FTP to the Enhanced Customer Data Repository (ECuRep)
See the Related information article,Submitting diagnostic information to IBM Technical Support for problem determination
A Discussion of the Application Porting Issues Informix Dynamic Server Version 7.3x
CHAP 1. 소개
CHAP 2. DDL
2.1 식별자(Identifiers)
식별자는 데이터베이스, 테이블, 컬럼, 인덱스, 뷰, 프로시저 등의 데이터베이스 오브젝트를 나타내는 이름이다.
2.2 데이터베이스 (Databases)
※ ANSI 데이터베이스의 특징 트랜잭션이 암시적(implicitly)으로 정의되므로 begin work 문장이 필요없이 모든 문장이 트랜잭션안에 들어간다. 데이터베이스의 모든 오브젝트는 소유자(owner)의 이름을 필요로 한다. Grant to public 개념이 없으므로 각각의 사용자에게 권한을 부여해야 한다.
2.3 테이블 (Tables)
※ constraint 정의 구문 예제
※ Informix의 alter table 구문은 좀 더 풍부한 기능을 제공한다 - 컬럼 추가 및 삭제, 컬럼명 변경, next size변경, lock mode변경 등
3.1.1 selects 데이터를 읽어오는데 가장 적합한 방법을 옵티마이저가 어떻게 결정하느냐에 의해 질의가 실행 된다. 오라클과 인포믹스 7.3버전 이후 서버는 select문에서 옵티마이저 힌트를 사용할 수 있다.
3.1.2 Optimizer Directives 인포믹스 7.3이후 부터 오라클과 흡사한 옵티마이저 지시자(directives)를 제공한다. 질의가 수행될 때의 첫번째단계는 질의에 대한 최적화 경로를 찾아 컴파일하고 두번째 단계로 결과값을 출력한다.
인포믹스의 옵티마이저 지시자는 오라클의 옵티마이저 힌트와 구문과 동작에서 호환성이 있다. 지시자는 '+'기호가 따라오는 주석(comment)안에서 사용된다. 예) select {+ ORDERED AVOID FULL(e)} * from employee e, department d where e.dept_no = d.dept_no;
오라클의 직접적인 힌트외에 인포믹스는 유일하게 negative directives 의 개념을 제공한다. 즉, 옵티마이저가 피하는 (avoid) 최적화 방법을 지시할 수 있다. 또한 set explain 의 출력결과에서 옵티마이저 지시자에 대한 모든 정보를 알 수 있어 지시어의 의미 또는 구문 에러를 표시할 수 있다.
옵티마이저 지시자는 다음과 같은 최적화 프로세스를 제어할 수 있다 · Access methods: 인덱스 또는 전체 스캔. · Join Methods: hash join 또는 nested loop joins. · Join Order: 지정한 테이블 순서에 의해 join · Goal: first rows 또는 all rows (최초 응답시간 대 전체 산출 결과).
3.1.3 Inserts INSERT INTO…SELECT 구문을 사용할 때 인포믹스는 select절에 union 을 사용할 수 없고, INSERT INTO…VALUES 에서 수식이나 select절을 사용할 수 없다. 이러한 경우 select에 대한 결과를 INTO TEMP 절을 사용하여 임시테이블을 생성하고, INSERT INTO…SELECT 절 구문을 임시테이블로 부터 읽어와서 입력하도록 재작성해야한다.
3.1.4 Deletes
오라클의 DELETE table_name 구문은 DELETE FROM table_name 구문으로 고쳐야한다
3.1.5 Temporary Tables 인포믹스와 오라클의 temporary table은 개념에 있어서 많이 다르다. 오라클의 temporary table은 하나의 필드를 포함하는 배열과 같이 구현되어 있다. 인포믹스의 temporary table은 일반 테이블과 동일하게 구현되어 생성, 변경, 삭제 등의 작업을 할 수 있지만, 세션안에서만 유효하다.
3.1.6 Joins 오라클의 outer join 구문 + (조인 테이블의 컬럼에 부합하지 않는 값을 가진 컬럼의 뒤에 붙는다) 는 인포믹스의 OUTER 구문과 동일하다. OUTER 키워드는 테이블명 앞에 붙는다. 오라클과는 달리 괄호로 그룹화되어 복합(multiple) outer join을 허용한다.
오라클의 INTERSECT와 MINUS 오퍼레이터는 UNION과 비슷하다. INTERSECT는 인포믹스에서 WHERE EXISTS 나 WHERE … IN으로 교체할 수 있고, MINUS는 WHERE NOT EXISTS 또는 WHERE … NOT IN으로 교체할 수 있다.
인포믹스의 UNION은 대응되는 select 리스트의 자료형이 일치해야한다. 만약 그렇지 않을 경우 컬럼 리스트를 변경하거나 자료형을 바꿔야한다.
3.1.7 Order by, Group by 인포믹스에서는 ORDER BY절 또는 GROUP BY절에 사용하는 컬럼 리스트가 반드시 select리스트에 나타나야 한다.
3.1.8 Sorts 오라클에서의 NULL값을 가장 높은 값이고 인포믹스에서는 가장 낮은 값이다. 그러므로 오름차순으로 정렬을 할 경우 인포믹스에서는 NULL값이 먼저 출력된다. 이를 오라클과 동일한 순서로 변형시키기 위해서는 NULL값을 가장 높은 값으로 만들어 정렬할 수 있도록 stored procedure를 작성하고, 정렬이 끝나고 출력될 때 다시 NULL으로 교체하도록 하여야 한다.
3.1.9 Exceptions 하드 코딩된 오라클의 에러코드 값은 인포믹스의 에러 코드 값으로 교체해야한다.
3.1.10 Correlation Names UPDATE나 DELETE의 메인 테이블에 대해 correlation name을 사용할 수 없다.
3.1.11 Aliases 테이블에 alias 를 주면 원본 테이블명을 select 리스트나 where절에서 사용할 수 없다.
3.1.12 Hierarchical Queries 인포믹스는 B-트리 형태의 계층적으로 구성된 질의 결과를 만들지 않는다. 오라클은 START WITH 와 CONNECT BY PRIOR 절을 사용하여 구현한다. START WITH 는 루트 노드의 행을 지정하고, CONNECT BY에서 부모 노드와 자식 노드의 관계를 서술 한다. 이때 PRIOR 수식을 가장 먼저 확인한다.
다음 예는 JOB이 PRESIDENT인 직원을 루트 노드로 하여 그 아래 모든 하위 노드를 출력하는 질의어이다.
SELECT ename, empno,
mgr, job
FROM emp
START WITH
job = 'PRESIDENT'
CONNECT BY PRIOR
empno = mgr
오른쪽 테이블은 위의 질의 결과를 도식화하여 나타낸 것이다. 위와 같은 기능을 인포믹스에서 사용하려면 stored procedure나 function을 작성하여 cursor 또는 array를이용해야 한다. 인포믹스의 global array가 도움이 될 것이다.
3.2 호스트 변수 (Host Variables)
데이터 형에 따라 호스트 변수의 포맷을 변경할 필요가 있을 수 있다. 예를 들어 number나 date같은 자료형은 인포믹스에서 동일한 포맷으로 지원되지 않으므로 SQL문장안에서 포맷을 정의하는 절차를 거쳐야 한다.
예를들어 오라클 함수 TO_CHAR는 날짜와 숫자 값의 포맷을 사용한다. 비슷한 방식으로 인포믹스는 7.3 버전 이후 TO_DATE와 TO_CHAR 함수를 추가하였다. 또한 ESQL/C에서는 오라클의 날짜 포맷에 대응하여 인포믹스 날짜 포맷을 출력하는 ifx_to_gl_datetime() 함수를 가지고 있다.
위의 경우 포맷은 인포믹스에서 제공하는 값을 사용해야하며 오라클의 모든 포맷을 반 드시 포함하고 있는것은 아니다.
3.3 날짜 및 시간 함수 (Date and Time Functions )
현재 날짜를 처리하기 위하여 오라클은 SYSDATE를 사용하는데, 인포믹스에서는 다음과 같이 자료형에 따라 다르게 표현한다.
SQL문으로 현재 시스템 날짜를 얻기 위하여 SELECT DISTINCT TODAY FROM SYSTABLES 와 같이 사용한다. 또한 ESQL/COBOL의 ECO_TDY()함수나 ESQL/C의 rfmtdate()함수에서도 제공된다.
인포믹스는 오라클의 macro를 지원하지 않으므로 코드에서 제거해야하고 관련된 로직은 인포믹스에서 동일하게 구현될 수 있다.
3.9 Pseudo-Columns
Pseudo-columns 은 테이블에는 존재하지만 SELECT * FROM table_name 과 같은 질의에서는 나타나지 않는 컬럼이다. 인포믹스에서 pseudo-column은 일반적으로 DBMS엔진에 의해 사용되므로 이러한 컬럼을 어플리케이션에서 직접적으로 사용하지 않는것이 향후 어플리케이션 이식성이나 어플리케이션 변경에 도움이 된다.
3.9.1 LEVEL 오라클에서 hierarchical query를 할때 pseudo-column LEVEL 은 루트노드에 대하여 1을 리턴하고 그 루트노드의 자식 노드는 2를 노드 2가 부모인 자식 노드는 3을 등등.. 이러한 형태로 출력된다. 질의에서 hierarchical 관계를 정의하려면 START WITH CONNECT BY 문을 사용한다. 인포믹스는 hierarchical 질의를 지원하지 않으므로 LEVEL 컬럼을 사용하지 않는다.
3.9.2 ROWID 오라클의 ROWID 컬럼은 각 데이터 행의 주소를 나타낸다. 출력되는 ROWID는 다음과 같은 정보를 가지고 있다.
· 데이터파일에서 데이터 블럭의 정보 · 데이터블럭에서의 행의 정보 (첫번째 행이 0) · 데이터파일 정보 (첫번째 파일이 1)
대부분 데이터베이스에서 한 행을 나타내는 ROWID는 유일한 값을 가지지만 서로 다른 테이블에서 동일한 클러스터안에 저장된 행은 동일한 ROWID를 가진다. ROWID 컬럼의 값은 오라클의 ROWID 자료형으로 저장된다.
ROWID는 새로 지워지고 새로 입력되면 새로운 값이 할당되므로 이 컬럼을 테이블의 primary key로 사용하지 말아야 한다. 또, ROWID 컬럼값은 입력,수정,삭제 될 수 없다.
SELECT ROWID, ename
FROM emp
WHERE deptno = 20
오라클의 ROWID는 인포믹스의 ROWID와 거의 동일하게 동작한다. 하지만 저장되는 자료형은 서로 다르다.
3.9.3 ROWNUM 오라클에서 ROWNUM 컬럼값은 선택된 결과 레코드의 순서를 나타낸다. 다음과 같은 질의는 첫번째 9개 행을 출력한다.
SELECT * FROM emp WHERE ROWNUM < 10
이런 ROWNUM을 이용하여 테이블의 각 행에 유일한 값을 할당할 수 있다.
UPDATE tabx SET col1 = ROWNUM
오라클은 각 행을 읽어온후 ROWNUM을 할당하고 ORDER BY절에 의해 정렬되므로 ORDER BY에 의한 순서와 ROWNUM 순서가 다를 수 있다. 그러나 ORDER BY절에 사용되는 컬럼이 인덱스를 사용한다면 순서가 같아진다. 다음과 같은 질의는 아무런 행도 리턴하지 않는다.
SELECT * FROM employee WHERE ROWNUM > 1
첫번째 행을 가져와서 ROWNUM을 1로 할당하므로 조건에 맞지 않아 출력되지 않는다. 두번째 행이 출력되기 위해서는 ROWNUM이 1로 다시 할당되는 이때도 조건에 맞지 않기 때문에 출력되지 않고 이후의 모든 행이 마찬가지 상태가 된다.
인포믹스는 ROWNU과 동일한 컬럼을 가지고 있지는 않지만 FIRST N 구문을 이용하여 구현할 수 있다.
인포믹스는 다음과 같은 복합적인 경우에는 사용할 수 없다.
· subqueries · into temp 문 · view 정의 · stored procedure · union 질의
ORDER BY 없이 FIRST N구문을 사용하면 의미없는 순서로 데이터가 출력될 것이다.
/* 월급이 가장 많은 10명을 출력 */ SELECT FIRST 10 name, salary FROM emp ORDER BY salary; /* 10개의 최고 월급 출력 */ SELECT FIRST 10 DISTINCT salary FROM emp ORDER BY salary;
인포믹스 7.3은 "FIRST"란 이름으로 컬럼명을 사용할 수 있다. 따라서 "FIRST" 뒤에 양의 정수가 따라 오지 않는 경우는 테이블의 컬럼명으로 생각한다. N값은 1에서 231 - 1 까지 사용할 수 있다.
UPDATE tabx SET col1 = ROWNUM
위와 같은 오라클의 ROWNUM을 할당하는 구문의 경우 ESQL/C 로 아래와 같이 구현한다.
int counter = 0;
EXEC SQL declare c1 cursor for
SELECT col1, col2
INTO :col1, :col2
FROM table 1
WHERE col1 = "XX";
EXEC SQL open c1;
while (SQLCODE == 0) {
EXEC SQL fetch c1;
counter++; /* Increment counter for each row fetched */
if (counter >= 5) {
break;
/* logic... */
} /* End if */
} /* End while */
3.10 커서를 이용한 수정 (Update Using Cursors )
인포믹스와 오라클의 커서는 약간의 차이가 있다. 오라클과는 달리 인포믹스에서는 FOR UPDATE 커서가 여러 테이블을 조인하는 경우에는 사용할 수 없으므로 WHER CURRENT OF 문장을 테이블 조인상태에서 사용할 수 없다. 따라서 테이블을 조인해야할 경우는 동일한 커서 루프에서 WHERE CURRENT OF 문장을 제거하고 UPDATE문장을 분리하여야 한다.
인포믹스에서 commit 또는 rollback 문은 트랜잭션안에서오픈된 모든 커서를 닫는다. 커서를 닫지 않고 commit 또는 rollback을 실행하여야 할 경우 HOLD 커서를 선언할 수 있다. 그러나 HOLD커서는 FOR UPDATE 문에서 사용될 수 없다. 따라서 오라클에서 fetch 루프안에서 업데이트하거나 commit하는 어플리케이션은 인포믹스의 형태로 변환해야한다. 커서는 HOLD를 사용하여 선언하고 업데이트 문장은 WHERE CURRENT OF 문장 없이 사용한다. WHERE CURRENT OF 문장의 의미를 나타내기 위하여
WHERE ROWID = fetch된 rowid값 또는 WHERE primary key 컬럼 = fetch된 primary key 컬럼값
형태로 작성한다.
오라클의 트랜잭션 내의 fetch 루프를 구현하기 위하여 BEGIN WORK 문장이 COMMIT WORK 나 ROLLBACK WORK 문장에 바로 따라 올 수 있도록 한다.
3.11 시스템 테이블(System Tables )
오라클의 시스템 테이블 참조는 이에 대응되는 인포믹스의 시스템 카타로그 테이블 차조로 교체할 수 있다.
3.12 스토어드 프로시저 (Stored Procedures)
3.12.1 Size 인포믹스의 stored procedure는 대략 64K의 한계가 있다. 오라클의 64K가 넘는 procedure는 좀더 작은 단위로 쪼개고 필요한 매개변수와 리턴값을 서로 주고 받을 수 있도록 한다.
3.12.2 Packages 오라클의 stored function과 stored procedure는 인포믹스의 stored procedure로 교체할 수 있다. 그러나Package body는 stored procedure와 stored function의 그룹을 포함하고 있고 package는 stored procedure와 stored function의 리스트를 가지고 있다. 모든 package body는 인포믹스의 개별적인 stored procedure로 재작성해야 하고 package 레벨의 변수는 인포믹스의 global 변수로 대응시켜야 한다.
3.12.3 Exceptions 오라클은 CURSOR_ALREADY_OPEN, NO_DATA_FOUND, ZERO_DIVIDE 등과 같이 미리 정의되거나 사용자 정의된 exception label을 가지고 있다. EXCEPTION 구조를 사용한 BEGIN/END 블럭에서 하나의 exception 만 허용되고 보통 END 문 바로 앞에 EXCEPTION 처리문이 위치 한다.
인포믹스 또한 미리 정의되거나 사용자가 정의한 exception을 지원하지만 표현 방식이 label형태가 아니고 숫자로 나타난다. 모든 exception은 stored procedure의 control block에서 체크되고, 각 control block의 상단부에 EXCEPTION문으로 명시적으로 선언해야한다.
3.12.4 Error Handling SQLCA 구조체는 stored procedure에서 완벽하게 지원하지 않는다. SQLCODE 변수 체크는 불가능하다. 대신 DBINFO 함수를 사용해 sqlca.sqlerrd1과 sqlca.sqlerrd2 값을 추출해 낼 수 있다. 이 함수는 커서가 열린FOREACH 문안에서 사용될 수 있다.
3.12.5 Cursors 오라클의 global 커서는 인포믹스에서 temporary 테이블을 통하여 구현한다. 오라클 procedure에서는 커서를 명시적으로 선언하고 오픈하지만 인포믹스에서는 procedure안에서 명시적으로 커서를 선언할 필요 없다. 따라서 오라클의 procedure 커서는 인포믹스의 FOREACH 구조로 변환할 수 있다.
우선 게시판 성격에 맞지 않는 글을 올려서 죄송합니다. devel이나 튜토리얼쪽에는 쓰기권한이 없어서 정보를 공유하고자 여기에 올립니다.
DB내의 쿼리를 쓰면서 Shell 에서도 유용하게 쓸 수 있는 Script 작성 방법을 알려드리고자 합니다. 다 아시다시피 Scipt는 컴파일 할 필요도 없고 어떤 시스템에서도 구동할 수 있다는 장점이 있어서 많은 시스템 관리자들이 유용하게 사용들을 하고 있죠. 이런 Script 내에서 SQL문을 삽입하여 사용을 할 수 있는 방법이 있습니다.
다음의 4가지 예제를 통하여 확인해보시고 각자에 맞게 확장된 script를 만들어서 유용하게 사용하시기 바랍니다.
아래의 예제는 informix의 가장 기본적인 sample인 stores_demo를 이용해서 만들어졌습니다.
1. 직접입력(Redirecting input)
#!/bin/sh
dbaccess <<SQLSTMT
database stores_demo;
select customer_num, fname, lname, company from customer;
SQLSTMT
----------------
sql문을 실행함으로 결과값을 얻을 수 있는 간단한 shell 입니다. 여기서 보이고 있는 SQLSTNT는 단순한 입력 한자리 단어로 마음에 드는 것으로 바꾸어 사용해도 잘 실행이 됩니다. 주의할 점은 sql문 시작시와 끝날때 꼭 같이 넣어주어야 한다는 것입니다.
2. 직접출력(redirecting output)
#!/bin/sh
{
dbaccess 2>error.log <<SQLSTMT
database stores_demo;
select customer_num, fname, lname, company from customer;
SQLSTMT
} | more
---------------------------
error.log 라는 필드를 넣음으로 shell 실행 시 발생되는 messages를 저장할 수 도 있고 { } 를 사용한 이후 pipe를 이용하여 more 같은 unix의 다른 프로그램 사용도 가능합니다.
3. Shell변수이용(Using Shell Variable)
#!/bin/sh
echo "Enter company name (use * for wildcard matches) to find"
echo "Company : \c"
read comp
dbaccess 2>error.log <<SQLSTMT
database stores_demo;
select customer_num, fname, lname, company from customer
where company matches "$comp";
SQLSTMT
----------------------------
Shell의 변수들을 이용하여 값을 얻어낼 수 도 있습니다. shell 상에서 comp에 값을 입력해주면 where 구문에서 변수값으로 받아 찾아낸 값을 출력해주는 방식입니다. 이런 정도만 사용하는 곳이라면 복잡하게 프로그램 짜거나 일일히 db에 접속하지 않고 단순히 shell만 돌려도 되겠죠?
4. Unix 프로그램에 Shell을 이용해 얻어낸 Data 사용(Getting Data into Shell Variables)
#!/bin/sh
today=`date +%m/%d/%y` # get today's date
{
dbaccess 2>error.log <<SQLSTMT
database stores_demo;
output to pipe "pr -t" without headings
select customer_num, fname,lname,company from customer;
SQLSTMT
} | while read line # pipe the output to while read
do
if [ "$line" ] # check if line is not NULL
then
# First parse the line into words/variables using set
set $line # assign the line to positional variables
name="$2 $3" # get the second and third variable for name
# company name may include spaces, $4 is only the first word
# so we discard the first 3 positions and assign the
# rest of the line to the comp variable
shift 3 # discard the first three variables
comp="$*" # let all remaining variables = the company
## Start of simple form letter`
echo "Date: $today"
echo "To: $name"
echo " $comp"
echo "Thank you for your business"
echo " "
fi
done
----------------------------------------
output이라는 sql내의 명령문을 이용해서 unix의 다른 프로그램으로도 연결할 수 있습니다. 이 예제는 메일머지에 사용된 예제입니다. 다음은 결과입니다.
.............
Date : 03/07/08
To : Chris Putnum
Putnum's Putters
Thank you for your business
Date : 03/07/08
To : James Henry
Total Fitness Sports
Thank you for your business
................
머.. 이 간단한 예제를 더욱 발전시켜서 여러분들의 환경에 잘 써보시기 바랍니다. 아참, 이것은 제가 만든것이 아니고 IIUG의 memeber중의 한명이 Lester Knutsen이 만든것입니다. 다음은 원문입니다.
Simple shell scripts play a role in small programs and very complex applications.
One of the advantages of Unix and Linux is the ability to use scripts for developing systems and programs. I’ll introduce you to using shell scripts with embedded SQL to access your database. Shell scripts are easy to write, they don’t need to be compiled, and are great for small batch programs.
Shell scripts do have their limits. They don’t provide a nice GUI interface and, because they aren’t compiled, everyone gets to see the source code. These limitations, though, are minor trade-offs.
In these examples, I use an Informix database and the Informix SQL command interpreter dbaccess. However, the examples will also work with Informix isql — and should work with any database that lets you redirect standard input and output. The basic items I’ll explore are: redirecting input and output, passing shell variables to SQL, and setting shell variables with the results of SQL commands.
Redirecting Input
One way to include SQL commands in a shell script is to redirect standard input to dbaccess from within the shell script. The example shell script in Listing 1 takes an SQL statement and redirects the SQL so that it is executed by dbaccess.
When dbaccess starts, it expects a database name and SQL script name as its arguments; if they’re not available, dbaccess will display menus and prompt you for them. The two dashes (- -) indicate to dbaccess that the database and commands will come from standard input. The << indicates to the shell that standard input is redirected and that everything between the two occurrences of SQLSTMT is to be passed to dbaccess as standard input. This is called a “here document” in Unix shell scripts.
The program dbaccess treats these lines as if you had typed them in from the keyboard. This is like typing dbaccess - - < filename, where filename is a file with the SQL commands. You don’t have to use SQLSTMT, but you do need two identical words to mark the beginning and end of input redirection. Running this script will start dbaccess and process SQL commands. The first command will open the stores_demo database and the next command will display the name and company of all the customers. You can use any valid SQL command that dbaccess will execute.
Redirecting Output
If you have a large customer table, the output will scroll off the screen. Like most Unix programs, Informix dbaccess will send output to two standard devices that are normally defined as your terminal window. Data goes to standard output, and processing messages go to standard error. In Listing 1, the names and companies are sent to standard output and the two messages (Database selected and 99 row(s) retrieved) are sent to standard error. These can be redirected to a file by changing line 2 in Listing 1 to:
dbaccess - - >cust.rpt 2>error.log <<SQLSTMT
The first > sends standard out (data) to a file cust.rpt and the 2> sends standard error (messages) to an error.log.
What’s more useful is to send data to a paging program (such as more) and messages to a log file (see Listing 2).
Notice that I’ve removed the first > and added a pair of { }. The pair of { } instruct the shell to execute the enclosed statements as a group. This instruction is useful to pipe the output to another program, such as more.
Using Shell Variables
You can use shell variables and prompts with SQL. The example in Listing 3 prompts for a company name and passes the variable to SQL for use in the SELECT statement. Entering an A* at the prompt would select all companies whose names begin with the letter A.
Getting Data Into Shell Variables
The results of an SQL command can be inserted into shell variables. The following is a simple example of a mail-merge program, selecting names and companies from a database, setting shell variables, and merging that data with some text. There are better ways to do this with the programming tools that come with a database, but this example illustrates the power of embedding SQL in shell scripts (see Listing 4).
In this example, the output is sent to a WHILE loop. The WHILE loop reads each line of output until it’s done. Each line is broken apart into words by the set command. The first word is assigned $1, the second $2, and so on. name=”$2 $3” gets the name of the person. The company name is more difficult because it may contain spaces. The name “Big Company” would be broken into to two variables. The command shift 3discards the first three variables, and what was $4 becomes $1. All remaining variables are assigned to the company name with comp=$*.
Mastering Complexity
I’ve just scratched the surface of what you can do with embedded SQL in shell scripts. Many complex applications, such as billing and scheduling systems, are built using SQL in shell scripts. Now you have the tools to put this technique to use.
Lester Knutsenis president of Advanced DataTools Corp., an IBM Informix consulting and training partner specializing in data warehouse development, database design, performance tuning, and Informix training and support. He is president of the Washington D.C. Area Informix User Group, a founding member of the International Informix Users Group, and an IBM gold consultant.
 ONBARS FUNCTIONAL SPECIFICATIONS
ONBARS FUNCTIONAL SPECIFICATIONS